

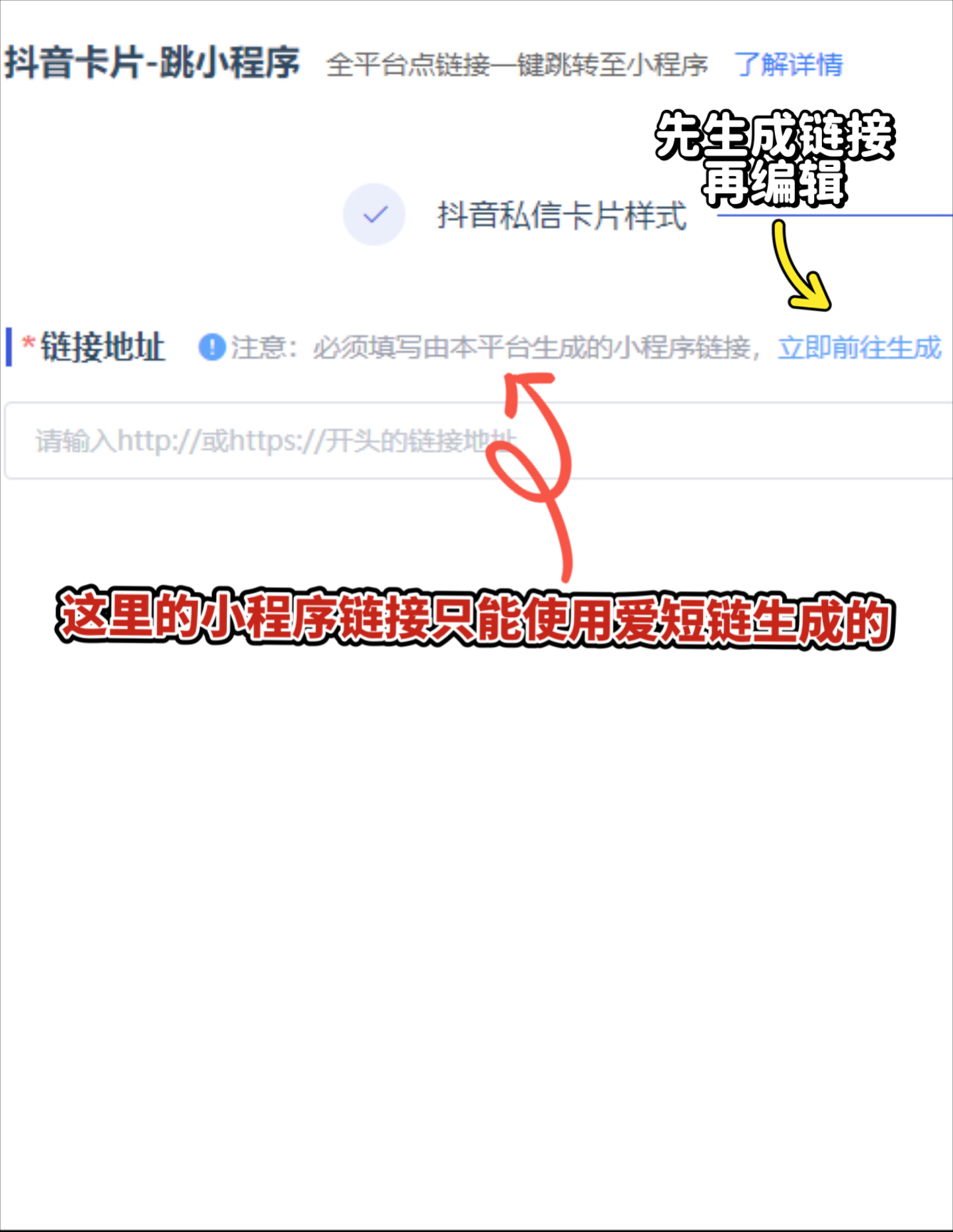
抖音用戶id怎么獲取?抖音uid是什么賬號(hào)?
本文根據(jù)【2016 第七屆中國數(shù)據(jù)庫技術(shù)大會(huì)】現(xiàn)場(chǎng)演講嘉賓 孫玄老師分享內(nèi)容整理而成。錄音整理及文字編輯IT168@ZYY@老魚
講師簡(jiǎn)介
▲孫玄
58集團(tuán)高級(jí)系統(tǒng)架構(gòu)師,58集團(tuán)技術(shù)委員會(huì)主席&架構(gòu)組主任,產(chǎn)品技術(shù)學(xué)院優(yōu)秀講師,58同城即時(shí)通訊、轉(zhuǎn)轉(zhuǎn)架構(gòu)算法部負(fù)責(zé)人,擅長(zhǎng)系統(tǒng)架構(gòu)設(shè)計(jì),分布式存儲(chǔ)等技術(shù)領(lǐng)域。代表58同城多次參加QCon,SDCC,DTCC,Top100,Strata+Hadoop World,WOT等大會(huì)嘉賓演講,并為《程序員》雜志撰稿2篇。 前百度高級(jí)工程師,參與社區(qū)搜索部多個(gè)基礎(chǔ)系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)。畢業(yè)于浙江大學(xué)。“架構(gòu)之美”作者。
正文
大家好,我是來自58的孫玄,今天分享的主題是《MongoDB在58同城的應(yīng)用實(shí)踐》,主要內(nèi)容如下所示:
首先介紹一下MongoDB在58的使用情況,從2011年到2014年,58基本使用了三年MongoDB,三年中,整個(gè)公司的業(yè)務(wù)線都在大規(guī)模使用MongoDB。在2014年,由于技術(shù)選型的改變,58配合業(yè)務(wù)特點(diǎn)做了一些調(diào)整。14年和15年,58基本很少使用MongoDB,但隨著趕集和英才對(duì)MongoDB的頻繁使用,58于今年又開始大規(guī)模使用MongoDB。
就我個(gè)人而言,從15年開始真正使用MongoDB,主要應(yīng)用在業(yè)務(wù)線上,所以分享的內(nèi)容主要針對(duì)15年之前MongoDB在58的應(yīng)用案例和實(shí)踐。隨著MongoDB社區(qū)的發(fā)展,特別是3.0的崛起,可能會(huì)略有不足。以上便是此次分享的背景,接下來切入主題。
基本上在2014年底,58比較核心的業(yè)務(wù)線都在使用MongoDB,包括IM,交友,招聘,信息質(zhì)量,測(cè)試以及趕集和英才。現(xiàn)在最核心的數(shù)據(jù)存儲(chǔ)也是采用MongoDB在做,后期由于技術(shù)選型以及業(yè)務(wù)調(diào)整,使用量有所下降。
接下來講一下選用MongoDB的原因,作為一款NoSQL產(chǎn)品,選擇的同時(shí)我們會(huì)考慮到它的特性,主要有如下幾方面:
一是擴(kuò)展性,MongoDB提供了兩種擴(kuò)展性,一種是Master—Slave,基于主從復(fù)制機(jī)制,現(xiàn)在58用的比較多的是Replic Set,實(shí)際上就是副本集結(jié)構(gòu)。我們會(huì)針對(duì)不同的業(yè)務(wù)項(xiàng)進(jìn)行垂直拆分。
二是高性能,MongoDB在3.0之前,整個(gè)的存儲(chǔ)引擎依賴于MMAP。MMAP是整個(gè)的寫內(nèi)存,就是寫磁盤。數(shù)據(jù)寫入內(nèi)存之后,要通過操作系統(tǒng)的MMAP機(jī)制,特別做數(shù)據(jù)層的,如果數(shù)據(jù)存多份的話,就可能會(huì)造成數(shù)據(jù)不一致的問題。MongoDB在提供高性能的同時(shí),數(shù)據(jù)只存一份。這種情況下,設(shè)計(jì)提供高性能的同時(shí),可以很好地解決數(shù)據(jù)一致性問題。
除此之外,MongoDB也有其他一些特性,包括豐富的查詢,full index支持和Auto-Sharding。另外,做任何選擇一定要結(jié)合業(yè)務(wù)邏輯。58原來是分類信息網(wǎng)站,主要的業(yè)務(wù)特征是并發(fā)量比較大,但58和電商的自主交易不同,對(duì)事務(wù)沒那么高要求。在這種場(chǎng)景下,選擇MongoDB作為核心存儲(chǔ)機(jī)制,是非常不錯(cuò)的選擇。
MongoDB不像關(guān)系型數(shù)據(jù)庫,必須定義Schema,MongoDB比較個(gè)性化,對(duì)Schema的支持也沒有那么嚴(yán)格,可以在表里隨意更改結(jié)構(gòu)。但free schema是否真的free嗎?比如原來的關(guān)系型數(shù)據(jù)庫,需要定義每一列的名稱和類型,存儲(chǔ)時(shí)只需存儲(chǔ)真正的數(shù)據(jù)就可以了,schema本身不需要存儲(chǔ)。由于MongoDB沒有schema的概念,存儲(chǔ)的自由度大了,但整個(gè)存儲(chǔ)空間會(huì)帶來一些額外開銷,畢竟要存儲(chǔ)字段名,value值無法改變,但可以減少字段名的長(zhǎng)度,比如age可以考慮用A表示。這時(shí)可能會(huì)出現(xiàn)可讀性問題,我們?cè)跇I(yè)務(wù)層做了映射,用A代表age。同時(shí),減小整個(gè)數(shù)據(jù)的字段名,通過上層映射解決可讀性問題。
另外我們還做了數(shù)據(jù)壓縮,其實(shí)我們有很多文本數(shù)據(jù),文本數(shù)據(jù)的壓縮率還是比較高的,我們對(duì)部分業(yè)務(wù)也采取了數(shù)據(jù)壓縮的方式。在Auto-sharding方面,我們采用庫級(jí)sharding,collection sharding采用手動(dòng)sharding。當(dāng)整個(gè)表的行數(shù)量比較大時(shí),會(huì)進(jìn)行拆分,把一些比較大的文檔切分成小文檔,包括這些文檔的嵌套存儲(chǔ),都是MongoDB相對(duì)于其他關(guān)系型數(shù)據(jù)庫而言比較優(yōu)秀的地方。
自動(dòng)生成_id其實(shí)就相當(dāng)于主鍵的概念,默認(rèn)的字段長(zhǎng)度是12個(gè)字節(jié),整個(gè)存儲(chǔ)空間的占用比較大,我們盡可能根據(jù)業(yè)務(wù)特征,在業(yè)務(wù)層把該字段填充成我們自己的字段。如果存儲(chǔ)用戶信息,該字段可以填成UID,因?yàn)閁ID最大是八個(gè)字節(jié)。一方面可以減小整個(gè)存儲(chǔ)空間,另一方面,雖說_id可以在MongoDB服務(wù)端生成,但我們盡可能把_id生成工作放在業(yè)務(wù)層或應(yīng)用層,可以減少M(fèi)ongoDB在服務(wù)端生成_id的開銷,寫入壓力比較大時(shí),整個(gè)性能的節(jié)省非常明顯。
接下來是部署層面,每一個(gè)分片上是Replica Set,同時(shí)開啟Sharding功能,基本結(jié)構(gòu)如上圖右邊所示,每個(gè)分片做一個(gè)Sharding,在Sharding上有Replica Set的概念。通過這個(gè)架構(gòu),所有configs直接通過mongos到shards。增加sharding或者在sharding上做增減,實(shí)際上對(duì)整個(gè)應(yīng)用是比較透明的。這樣部署一方面可以很好的滿足業(yè)務(wù)需求,另一方面可以很好地滿足內(nèi)部擴(kuò)展和故障轉(zhuǎn)移。
另一個(gè)比較隱蔽的話題就是sharding操作,大家可能都比較關(guān)心,Auto-Sharding到底靠不靠譜。就我個(gè)人理解而言,既然要用Auto-sharding,就要解決sharding key的問題。如果選用單一遞增的sharding key,可能會(huì)造成寫數(shù)據(jù)全部在最后一片上,最后一片的寫壓力增大,數(shù)據(jù)量增大,會(huì)造成數(shù)據(jù)遷移到前面的分區(qū)。如果選用隨機(jī)key,的確可以避免寫問題,但如果寫隨機(jī),讀就會(huì)出現(xiàn)問題,可能會(huì)出現(xiàn)大量隨機(jī)IO,對(duì)一些傳統(tǒng)磁盤而言影響是致命的。那如何選取合適的sharding-key呢?先要保證該key在整個(gè)大范圍內(nèi)單調(diào)遞增,這樣隨機(jī)選擇時(shí),可以保證相對(duì)均勻,不會(huì)引發(fā)其他問題。
此外,我們?cè)跍y(cè)試中發(fā)現(xiàn),數(shù)據(jù)遷移過程中經(jīng)常會(huì)出現(xiàn)一些問題。一旦發(fā)生數(shù)據(jù)遷移,比如從A遷到B片,數(shù)據(jù)可能同時(shí)存在于兩片數(shù)據(jù)上,直至遷移完成,整個(gè)數(shù)據(jù)才會(huì)全部存在于B片上。58的業(yè)務(wù)特點(diǎn)屬于中午訪問的人很少,這時(shí)MongoDB集群的負(fù)載比較低,系統(tǒng)會(huì)認(rèn)為此適合進(jìn)行數(shù)據(jù)遷移,將會(huì)開啟Auto-sharding。午飯時(shí)間結(jié)束之后,訪問量就開始逐漸增加。此時(shí),整個(gè)遷移尚未完成,不會(huì)立即停止,集群的OPS會(huì)瞬間從幾千掉到幾十,這對(duì)業(yè)務(wù)的影響非常大。這時(shí),我們會(huì)指定整個(gè)sharding的遷移時(shí)間,比如從凌晨?jī)牲c(diǎn)到早上六點(diǎn)這段時(shí)間屬于業(yè)務(wù)低峰期,這段時(shí)間可以允許sharding進(jìn)行業(yè)務(wù)遷移,同時(shí)開啟數(shù)據(jù)庫級(jí)別的分片。這樣可以避免Auto-sharding數(shù)據(jù)遷移帶來的問題。
另外,做整個(gè)設(shè)計(jì)特別是業(yè)務(wù)設(shè)計(jì)時(shí),一定要了解業(yè)務(wù)發(fā)展場(chǎng)景,比如半年或一年內(nèi),大概可以增長(zhǎng)到什么樣的規(guī)模,需要提前做預(yù)期。根據(jù)業(yè)務(wù)發(fā)展情況,就知道大概需要開多少分片,每一片放多少數(shù)據(jù)量合適。
做整個(gè)規(guī)劃時(shí),也需要考慮容量性能。至少要保證Index數(shù)據(jù)和Hot Data全部加載到內(nèi)存中,這樣才可以保證MongoDB的高性能,否則性能壓力還是蠻大的。2011年開始使用MongoDB時(shí),數(shù)據(jù)庫內(nèi)存是32g,后來一路上升至196g,其實(shí)隨著業(yè)務(wù)的發(fā)展,整個(gè)硬件投入成本也是蠻高的。實(shí)際上如果內(nèi)存足夠大,整個(gè)性能情況還是比較令人滿意的。
另外,MongoDB整個(gè)數(shù)據(jù)庫是按照文件來存儲(chǔ)的,如果有大量表需要?jiǎng)h除的話,建議將這些表放到統(tǒng)一的數(shù)據(jù)庫里,將會(huì)減少碎片,提高性能。單庫單表絕對(duì)不是最好的選擇,表越多,映射文件越多,從MongoDB的內(nèi)存管理方式來看,浪費(fèi)越多;同時(shí),表越多,回寫和讀取時(shí),無法合并IO資源,大量的隨機(jī)IO對(duì)傳統(tǒng)磁盤是致命的;單表數(shù)據(jù)量大,索引占用高,更新和讀取速度慢。
另外一個(gè)是Local庫,Local主要存放oplog,oplog到底設(shè)多少合適呢?根據(jù)58的經(jīng)驗(yàn)來看,如果更新比較頻繁而且存在延時(shí)從庫,可以將oplog的值設(shè)置的稍微大一點(diǎn),比如20G到50G,如果不存在延時(shí)從庫,則可以適當(dāng)放小oplog值。
針對(duì)業(yè)務(wù)場(chǎng)景設(shè)計(jì)庫和表,因?yàn)镸ongoDB實(shí)際上是帶有嵌入式功能的,比如以人為例,一個(gè)人有姓名,性別,年齡和地址,地址本身又是一個(gè)復(fù)雜的結(jié)構(gòu),在關(guān)系型數(shù)據(jù)庫里,可能需要設(shè)置兩張表。但在MongoDB里非常簡(jiǎn)單,把地址做成嵌套文檔就可以了。
表設(shè)計(jì)無非這幾種,一對(duì)一,一對(duì)多和多對(duì)多的關(guān)系,一對(duì)一關(guān)系比如用戶信息表,實(shí)際上就是明顯的一對(duì)一關(guān)系,類似于關(guān)系型數(shù)據(jù)的設(shè)計(jì),用uid替換_id,做一個(gè)主鍵就ok了。
一對(duì)多的關(guān)系比如用戶在線消息表,一個(gè)人其實(shí)可以收到很多消息,這是明顯的一對(duì)多關(guān)系,可以按照關(guān)系型數(shù)據(jù)庫來設(shè)計(jì),按行擴(kuò)展;也可以采用MongoDB嵌套方式來做,把收到的消息存在一個(gè)文檔里,同時(shí)MongoDB對(duì)一個(gè)文檔上的每一行會(huì)有限制,如果超過16兆,可能會(huì)出現(xiàn)更新不成功的情況。
多對(duì)多關(guān)系如上圖示例,整個(gè)包括Team表,User表,還有兩者之間的關(guān)系表。在關(guān)系型數(shù)據(jù)庫里,這是三張表,一張表是整個(gè)Team表的元數(shù)據(jù),另一張表是User表的元數(shù)據(jù),同時(shí)還有關(guān)系表,表示二者的包含關(guān)系。在MongoDB里,可以借助嵌套關(guān)系來完成這件事。
每次通過Team表中的teammates反查詢得到teamid,Teammates需要建立索引,具體設(shè)計(jì)可以參照上圖。當(dāng)整個(gè)表比較大的時(shí)候,可以做手工分表,這點(diǎn)與關(guān)系型數(shù)據(jù)庫類似。
當(dāng)數(shù)據(jù)庫中一個(gè)表的數(shù)量超過了千萬量級(jí)時(shí),我們會(huì)按照單個(gè)id進(jìn)行拆分,比如用戶信息表,我們會(huì)按照uid進(jìn)行拆分。比如一些商品表,既可以按照用戶來查詢,又可以按照整個(gè)人來查詢,這時(shí)候怎么辦呢?
首先對(duì)整個(gè)表進(jìn)行分表操作,infoid包含uid的信息,對(duì)infoid進(jìn)行水平拆分,既可以按照uid查詢,又可以按照infoid查詢,可以很好地滿足商品信息表的需求,整體思路還是按照水平拆分的方式。
起初,我們做了IM離線消息集合結(jié)構(gòu),也就是說,當(dāng)某人不在線時(shí),我可以把消息先存起來,待他上線時(shí),再把整個(gè)消息拉過去。在這個(gè)過程中考慮到發(fā)生物理刪除時(shí),更新壓力會(huì)比較大,我們采用邏輯更新,在表中設(shè)置flag字段,flag為0,表示消息未讀,flag為1表示消息已讀。批量刪除已經(jīng)讀取的離線消息,可以直接采用MongoDB的刪除命令,非常簡(jiǎn)單。但當(dāng)數(shù)據(jù)量比較大時(shí),比如達(dá)到5KW條時(shí),就沒那么簡(jiǎn)單了,因?yàn)閒lag沒有索引,我們晚上20點(diǎn)開始部署刪除,一直到凌晨依然沒有刪除完畢,整個(gè)過程報(bào)警不斷,集群的服務(wù)質(zhì)量大幅下降。
原因很簡(jiǎn)單,因?yàn)槟阋M(jìn)行刪除,實(shí)際上就是做了一個(gè)全表掃描,掃描以后會(huì)把大量冷數(shù)據(jù)交換到內(nèi)存,造成內(nèi)存里全都是冷數(shù)據(jù)。當(dāng)數(shù)據(jù)高峰期上來以后,一定會(huì)造成服務(wù)能力急劇下降。怎么解決呢?
首先把正在進(jìn)行的opid kill掉,至少先讓它恢復(fù)正常,另外可以在業(yè)務(wù)方面做優(yōu)化,最好在用戶讀完以后,直接把整個(gè)邏輯刪除掉就OK了。其次,對(duì)刪除腳本進(jìn)行優(yōu)化,以前我們用flag刪除時(shí),既沒有主鍵也沒有索引,我們每天定期從從庫把需要?jiǎng)h除的數(shù)據(jù)導(dǎo)出來,轉(zhuǎn)換成對(duì)應(yīng)的主鍵來做刪除,并且通過腳本控制整個(gè)刪除速度,整個(gè)刪除就比較可控了。
另外我們發(fā)現(xiàn),一旦大量刪除數(shù)據(jù),MongoDB會(huì)存在大量的數(shù)據(jù)空間,這些空洞數(shù)據(jù)同時(shí)也會(huì)加載到內(nèi)存中,導(dǎo)致內(nèi)存有效負(fù)荷低,數(shù)據(jù)不斷swap,導(dǎo)致MongoDB數(shù)據(jù)庫性能并沒有明顯的提升。
這時(shí)的解決方案其實(shí)很容易想到,MongoDB數(shù)據(jù)空間的分配以DB為單位,本身提供了在線收縮功能,不以Collection為單位,整個(gè)收縮效率并不是很好,因?yàn)槭莖nline收縮,又會(huì)對(duì)在線服務(wù)造成影響,這時(shí)可以采取線下的解決方案。
方案二,收縮數(shù)據(jù)庫,把已有的空洞數(shù)據(jù)remove掉,重新生成一份空洞數(shù)據(jù)。先預(yù)熱從庫,把預(yù)熱從庫提升為主庫,把之前主庫的數(shù)據(jù)全部刪除,重新同步數(shù)據(jù),同步完成后,預(yù)熱此庫,把此庫提升為主庫,完全沒有碎片,收縮率達(dá)到100%。但這種方式持續(xù)時(shí)間長(zhǎng),投入維護(hù)成本高,如果只有2個(gè)副本的情況下, 收縮過程單點(diǎn)存在一定風(fēng)險(xiǎn)。
這時(shí)在線上做對(duì)比,我們發(fā)現(xiàn),收縮前大概是85G的數(shù)據(jù)量,收縮之后是30G,大概節(jié)省了50G的存儲(chǔ)量,整個(gè)收縮效果還是蠻好的,通過這種方式來做還是比較好的。
另外講一下MongoDB的監(jiān)控,MongoDB提供了很多監(jiān)控工具,包括mongosniff,mongostat,mongotop,以及命令行監(jiān)控,還有第三方監(jiān)控。我們自己怎么做呢?
我們針對(duì)MongoDB本身的性能情況,用的比較多的是mongostat,可以反映出整個(gè)服務(wù)的負(fù)載情況,比如insert,query,update以及delete,通過這些數(shù)據(jù)可以反映出MongoDB的整體性能情況。
這其中有些字段比較重要,locked表示加鎖時(shí)間占操作時(shí)間的百分比,faults表示缺頁中斷數(shù)量,miss代表索引miss的數(shù)量,還包括客戶端查詢排隊(duì)長(zhǎng)度,當(dāng)前連接數(shù),活躍客戶端數(shù)量,以及當(dāng)前時(shí)間,都可以通過字段反映出來。
根據(jù)經(jīng)驗(yàn)來說,locked、faults、miss、qr/qw,這些字段的值越小越好,最好都為0,locked最好不要超過10%,faults和miss的原因可能是因?yàn)閮?nèi)存不夠,內(nèi)冷數(shù)據(jù)或索引設(shè)置不合理,qr|qw堆積會(huì)造成數(shù)據(jù)庫處理慢。
Web自帶的控制臺(tái)監(jiān)控和MongoDB服務(wù)一同開啟,可以監(jiān)控當(dāng)前MongoDB所有的連接數(shù),各個(gè)數(shù)據(jù)庫和collection的訪問統(tǒng)計(jì),包括Reads,Writes,Queries等,寫鎖的狀態(tài)以及最新的幾百行日志文件。
官方2011年發(fā)布了MMS監(jiān)控,MMS屬于云監(jiān)控服務(wù),可視化圖形監(jiān)控。在MMS服務(wù)器上配置需要監(jiān)控的MongoDB信息(ip/port/user/passwd等),在一臺(tái)能夠訪問你的MongoDB服務(wù)的內(nèi)網(wǎng)機(jī)器上運(yùn)行其提供的Agent腳本,Agent腳本從MMS服務(wù)器獲取到你配置的MongoDB信息,Agent腳本連接到相應(yīng)的MongoDB獲取必要的監(jiān)控?cái)?shù)據(jù),Agent腳本將監(jiān)控?cái)?shù)據(jù)上傳到MMS的服務(wù)器,登錄MMS網(wǎng)站查看整理過后的監(jiān)控?cái)?shù)據(jù)圖表。
除此之外,還有第三方監(jiān)控,因?yàn)镸ongoDB的開源愛好者對(duì)它的支持比較多,所以會(huì)在常用監(jiān)控框架上做一些擴(kuò)展。
以上是MongoDB在58同城的使用情況,包括使用MongoDB的原因,以及針對(duì)不同的業(yè)務(wù)場(chǎng)景如何設(shè)計(jì)庫和表,數(shù)據(jù)量增大和業(yè)務(wù)并發(fā)時(shí)遇到的典型問題及解決方案。
今天的分享到此結(jié)束,謝謝大家!
轉(zhuǎn)載請(qǐng)注明來自夕逆IT,本文標(biāo)題:《抖音用戶id怎么獲取?抖音uid是什么賬號(hào)?》
 京公網(wǎng)安備11000000000001號(hào)
京公網(wǎng)安備11000000000001號(hào) 京ICP備11000001號(hào)
京ICP備11000001號(hào)
還沒有評(píng)論,來說兩句吧...